1. scikit-learn 개요
머신러닝 분석을 수행할 때 가장 유용하게 사용할 수 있는 파이썬 라이브러리
1) scikit-learn 임포트
import sklearn
print(sklearn.__version__) #버전확인
2. scikit-learn 기반 프레임워크
머신러닝 모델 학습을 위한 fit 함수와 학습된 모델의 예측을 위한 predict 함수 제공
분류 알고리즘을 위한 클래스 Classifier, 회귀 알고리즘을 위한 클래스 Regressor

3. scikit-learn 주요 모듈
1) 예제 데이터
| 모듈 | 설명 |
| sklearn.datasets | scikit-learn에 내장되어 예제 데이터 세트를 제공 |
2) 변수 처리
| 모듈 | 설명 |
| sklearn.preprocessing | 데이터 전처리에 필요한 다양한 기능을 제공 (인코딩, 정규화, 스케일링 등) |
| sklearn.feature_selection | 알고리즘에 큰 영향을 미치는 변수들을 선택하는 작업을 수행하는 다양한 기능을 제공 |
| sklearn.feature_extraction | 텍스트 데이터나 이미지 데이터와 같이 벡터화된 변수를 추출하는데 사용 Count Vectorizer 등을 생성하는 기능 제공 텍스트 변수 추출 : sklearn.feature_extraction.text 모듈에 내장 이미지 변수 추출 : sklearn.feature_extraction.image 모듈에 내장 |
3) 변수 처리 & 차원 축소
| 모듈 | 설명 |
| sklearn.decomposition | 차원 축소와 관련한 알고리즘을 지원 PCA, NMF, Truncated SVD 등을 통해 차원축소 기능 수행 |
4) 데이터 분리, 검증 & 매개변수 튜닝
| 모듈 | 설명 |
| sklearn.model_selection | 학습데이터와 검증 데이터, 예측 데이터로 데이터를 분리하기 위해 활용하는 train_test_split 내장 최적의 하이퍼 매개변수로 모델을 평가하기 위한 다양한 함수와 기능 제공 |
5) 평가
| 모듈 | 설명 |
| sklearn.metrics | 분류, 회귀, 클러스터링 등에 대한 다양한 성능 측정 방법 제공 모델 평가를 위한 Accuracy, Precision, Recall, ROC-AUC, RMSE 등 제공 |
6) 머신러닝 알고리즘
| 모듈 | 설명 |
| sklearn.ensemble | 앙상블 알고리즘 제공 랜덤포레스트, 에이다 부스트, 그래디언트 부스팅 등 제공 |
| sklearn.linear_model | 선형 회귀, 릿지(Ridge), 라쏘(Lasso) 및 로지스틱 회귀 등의 회귀 관련 알고리즘 지원 SGD(stochastic Gradient Descent) 관련 알고리즘 제공 |
| sklearn.naive_bayes | 나이브 베이즈 알고리즘 제공 가우시안 NB, 다항 분포 NB 등이 있음 |
| sklearn.neighbors | 최근접 이웃 알고리즘 제공 KNN 등이 있음 |
| sklearn.svm | 서포트 벡터 머신 알고리즘 제공 |
| sklearn.tree | 트리 기반 머신러닝 알고리즘을 제공 의사결정 트리 알고리즘 등이 있 |
| sklearn.cluster | 비지도 클러스터링 알고리즘을 제공 K-평균, 계층형, DBSCAN 등이 있음 |
7) 유틸리티
| 모듈 | 설명 |
| sklearn.pipeline | 변수 처리와 같은 변환 작업과 머신러닝 알고리즘 학습, 예측 등 머신러닝 프로세스를 함께 묶어서 실행할 수 있는 유틸리티 제공 |
4. scikit-learn 내장 데이터 세트
1) 내장 데이터 세트
| 함수 | 설명 |
| datasets.load_boston | 회귀 목적, 미국 보스턴의 부동산 변수들과 가격에 대한 데이터 세트로 구성 |
| datasets.load_breast_canset | 분류 목적, 위스콘신 유방암 환자의 주요 변수들과 악성/음성 레이블 데이터 세트로 구성 |
| datasets.load_diabetes | 회귀 목적, 당뇨 환자의 주요 변수드륻이 데이터 세트로 구성 |
| datasets.load_digits | 분류 목적, 0에서 9까지 숫자의 이미지 픽셀 데이터 세트로 구성 |
| datasets.load_iris | 분류 목적, 붓꽃에 대한 주요 변수들의 데이터 세트로 구성 |
2) 표본 데이터 생성기
| 함수 | 설명 |
| datasets.make_classifications | 분류를 위한 데이터 세트 생성 높은 상관도, 불필요한 속성 등의 노이즈 효과가 적용된 데이터를 무작위로 생성할 수 있음 |
| datasets.make_blobs | 클러스터링을 위한 데이터 세트 생성 군집 지정 개수에 따라 여러가지 클러스터링을 위한 데이터 세트로 생성할 수 있음 |
3) 붓꽃 데이터 세트 불러오기
from sklearn.datasets import load_iris
iris=load_iris()
print('붓꽃 데이터세트 타입 : ',type(iris))
keys=iris.keys()
print('붓꽃 데이터세트 키 :' ,keys)''' 결과
붓꽃 데이터세트 타입 : <class 'sklearn.utils._bunch.Bunch'>
붓꽃 데이터세트 키 : dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module']) '''
4) 붓꽃 데이터 세트 키

print('feature_names : ')
print(iris.feature_names)
print('\ntarget_names : ')
print(iris.target_names)
print('\ndata : ')
print(iris.data)
print('\ntarget : ')
print(iris.target)''' 결과
feature_names :
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
target_names :
['setosa' 'versicolor' 'virginica']
data :
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
...
[6.7 3. 5.2 2.3]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
target :
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2] '''
5. scikit-learn 머신러닝 만들어 보기
붓꽃 데이터 세트로 붓꽃의 품종을 분류해보자.
독립변수 : 꽃잎의 길이와 너비, 꽃받침의 길이와 너비
종속변수 : 꽃의 품종(Setosa, Versicolor, Virginica)
1) 분류 개요
분류는 대표적인 지도학습 방법 중 하나로
학습을 위한 다양한 피처(Feature)데이터와 분류 결정값인 레이블(Label)데이터로 모델을 학습한 뒤
별도의 테스트 데이터 세트에서 미지의 레이블을 예측하여 분류한다.
2) 붓꽃 데이터 세트 흝어보기
데이터 프레임의 데이터에 iris.data 할당, 컬럼에는 iris.feature_names 할당
label 이라는 컬럼을 추가해 iris.target 데이터를 삽입했다.
import pandas as pd
iris_df=pd.DataFrame(data=iris.data,columns=iris.feature_names)
iris_df['label']=iris.target
print(iris_df.head(3))''' 결과
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
label
0 0
1 0
2 0 '''
3) 학습/테스트 데이터 세트 분할
학습/ 테스트 데이터 세트 분리를 위해 train_test_split을 임포트
train_test_split의 첫 번째 매개변수는 iris_data 피처 데이터 세트, 두 번째 매개변수인 iris_label은 타겟 데이터 세트이다.
test_size=0.2는 전체 데이터 세트 중 테스트 데이터 세트의 비율이다.
random_state=11는 함수 호출 시 같은 학습/데이터 세트를 생성하기 위해 주어지는 난수 발생 값으로 지정하지 않으면 수행 할 때마다 다른 세트가 생성된다.
아래의 예시에서는 학습 피처 데이터 세트를 x_train으로 학습 타겟 데이터 세트를 y_train으로 테스트 피처 데이터 세트를 x_test로 테스트 타겟 데이터 세트를 y_test로 생성했다.
from sklearn.model_selection import train_test_split
iris_data=iris.data
iris_label=iris.target
x_train,x_test,y_train,y_test=train_test_split(iris_data,iris_label,test_size=0.2,random_state=11)
print('train dataset')
print('x_train dataset : ', len(x_train))
print('y_train dataset : ', len(y_train))
print('test dataset')
print('x_test dataset : ', len(x_test))
print('y_test dataset : ', len(y_test))''' 결과
train dataset
x_train dataset : 120
y_train dataset : 120
test dataset
x_test dataset : 30
y_test dataset : 30 '''
4) 의사결정 트리 머신러닝 학습
의사결정 트리 클래스인 DecisionTreeClssifier을 객체로 생성하고 fit 함수에 학습 피처 데이터 세트인 x_train과 학습 타겟 데이터 세트인 y_train을 입력해 호출하면 학습을 수행할 수 있다.
from sklearn.tree import DecisionTreeClassifier
dt_clf=DecisionTreeClassifier(random_state=11)
dt_clf.fit(x_train, y_train)''' 결과
DecisionTreeClassifier(random_state=11) '''
5) 의사결정 트리 머신러닝 테스트/평가
학습을 수행한 의사결정 트리 클래스인 df_clf를 이용해 분류 예측을 수행한다.
예측은 학습 데이터가 아닌 테스트 데이터를 사용한다.
acuuracy_score 함수를 사용해 정확도를 측정한다.
첫 번째 매개변수로 타겟 데이터 세트를 두번째 매개변수로 예측 데이터 세트를 입력한다.
from sklearn.metrics import accuracy_score
pred=dt_clf.predict(x_test)
ac_score=accuracy_score(y_test,pred)
print('예측 정확도 : ',ac_score)''' 결과
예측 정확도 : 0.9333333333333333 '''
6) 머신러닝 모델 구현 프로세스
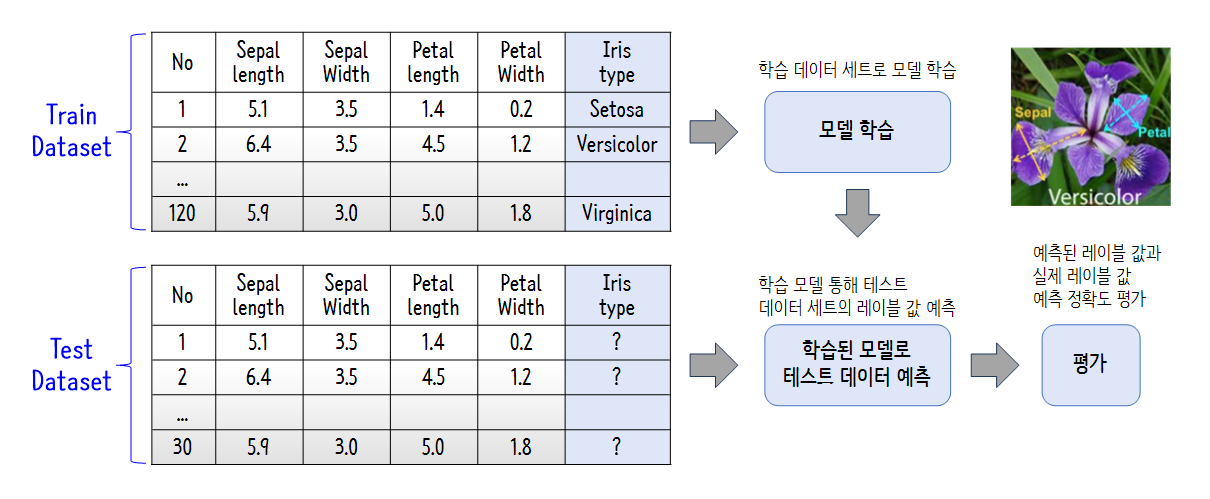
① 데이터 세트 분리 : 데이터 세트를 학습 데이터(Train Dateset)와 테스트 데이터(Test Dataset)으로 분리
② 모델 학습 : 학습 데이터를 기반으로 머신러닝 알고리즘을 적용해 모델을 학습
③ 예측 수행 : 학습된 머신러닝 모델을 이용해 테스트 데이터의 분류를 예측
④ 평가 : 예측된 결과 값과 테스트 데이터의 실제 결괏값을 비교해 머신러닝 모델의 성능을 평가
6. scikit-learn 데이터 전처리
결측치 허용 X : 얼마 되지 않는다면 평균값 대체, 대부분이라면 해당 데이터 삭제
문자열 값 허용 X : 명목형 변수는 코드 값으로 변환하여 처리
1) 레이블 인코딩
명목형 변수를 코드형 숫자 값으로 변환하는 것
LabelEncoder 클래스로 LabelEncoder를 객체로 생성한 후 fit과 transform을 호출해 레이블 인코딩 수행
from sklearn.preprocessing import LabelEncoder
items=['TV','냉장고','전자레인지','컴퓨터','TV','냉장고','컴퓨터','컴퓨터']
encoder=LabelEncoder()
encoder.fit(items)
labels=encoder.transform(items)
print('인코딩 변환값 : ',labels)
print('인코딩 클래스 : ', encoder.classes_)''' 결과
인코딩 변환값 : [0 1 2 3 0 1 3 3]
인코딩 클래스 : ['TV' '냉장고' '전자레인지' '컴퓨터'] '''
origins=encoder.inverse_transform([0,1,2,3,0,1,3,3])
print('디코딩 원본값 : ', origins)''' 결과
디코딩 원본값 : ['TV' '냉장고' '전자레인지' '컴퓨터' 'TV' '냉장고' '컴퓨터' '컴퓨터'] '''숫자 값의 크고 작음에 특성이 작용되는 몇몇 머신러닝 알고리즘에서 예측 성능이 떨어짐
2) 원-핫 코딩
변수 값의 유형에 따라 새로운 변수를 추가해 고유값에 해당하는 컬럼에만 1을 표시하고 나머지 컬럼에는 0을 표시
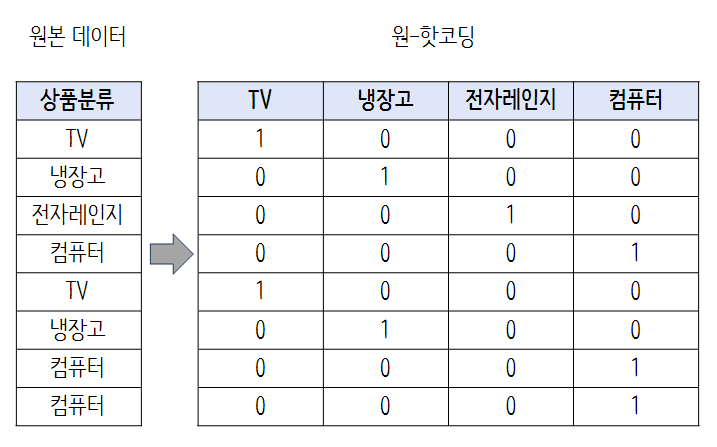
OneHotEncoder 클래스로 쉽게 변환가능하지만 다음 두 가지에 주의
1) OneHotEncoder로 변환하기 전에 모든 문자열 값이 숫자형으로 변환되어야 함
2) 입력 값으로 2차원 데이터가 필요
from sklearn.preprocessing import OneHotEncoder #sklearn 원-핫 인코딩
import numpy as np
labels=labels.reshape(-1,1) #2차원 데이터로 변환
oh_encoder=OneHotEncoder()
oh_encoder.fit(labels)
oh_labels=oh_encoder.transform(labels)
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)''' 결과
원-핫 인코딩 데이터
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]
[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]]
원-핫 인코딩 데이터 차원
(8, 4) '''
pandas에서는 명목형 데이터를 숫자형으로 변환할 필요 없이 get_dummies 함수를 이용해 바로 2차원 데이터로 변환
import pandas as pd
item_df=pd.DataFrame({'item' : items})
pd.get_dummies(item_df) #Pandas get_dummies 원-핫 인코딩''' 결과
item_TV item_냉장고 item_전자레인지 item_컴퓨터
0 1 0 0 0
1 0 1 0 0
2 0 0 1 0
3 0 0 0 1
4 1 0 0 0
5 0 1 0 0
6 0 0 0 1
7 0 0 0 1 '''
3) 스케일링
서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업
표준화 : 원 데이터를 평균이 0이고 분산이 1인 정규 분포를 가진 값으로 변환
정규화 : 서로 다른 변수의 크기를 통일하기 위해 크기를 변환해주는 개념
#데이터 세트 흝어보기
from sklearn.datasets import load_iris
import pandas as pd
iris=load_iris()
iris_data=iris.data
iris_df=pd.DataFrame(data=iris.data,columns=iris.feature_names)
print('feature 들의 평균 값 : \n', iris_df.mean())
print('feature 들의 분산 값 : \n', iris_df.var())''' 결과
feature 들의 평균 값 :
sepal length (cm) 5.843333
sepal width (cm) 3.057333
petal length (cm) 3.758000
petal width (cm) 1.199333
dtype: float64
feature 들의 분산 값 :
sepal length (cm) 0.685694
sepal width (cm) 0.189979
petal length (cm) 3.116278
petal width (cm) 0.581006
dtype: float64 '''StandardScaler 객체 생성 후 fit과 transform 함수에 변환 대상 데이터 세트를 입력하고 호출하면 간단하게 변환됨
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler.fit(iris_df)
iris_scaled=scaler.transform(iris_df)
iris_df_scaled=pd.DataFrame(data=iris_scaled,columns=iris.feature_names)
print('feature 들의 평균 값 : \n', iris_df_scaled.mean())
print('feature 들의 분산 값 : \n', iris_df_scaled.var())''' 결과
feature 들의 평균 값 :
sepal length (cm) -1.690315e-15
sepal width (cm) -1.842970e-15
petal length (cm) -1.698641e-15
petal width (cm) -1.409243e-15
dtype: float64
feature 들의 분산 값 :
sepal length (cm) 1.006711
sepal width (cm) 1.006711
petal length (cm) 1.006711
petal width (cm) 1.006711
dtype: float64 '''MinMaxScaler : 데이터 값을 0과 1 사이의 범위 값으로 변환
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
scaler.fit(iris_df)
iris_scaled=scaler.transform(iris_df)
irif_df_scaled=pd.DataFrame(data=iris_scaled,columns=iris.feature_names)
print('feature 들의 최소 값 : \m',iris_df_scaled.min())
print('feature 들의 최대 값 : \m',iris_df_scaled.max())''' 결과
feature 들의 최소 값 : \m sepal length (cm) -1.870024
sepal width (cm) -2.433947
petal length (cm) -1.567576
petal width (cm) -1.447076
dtype: float64
feature 들의 최대 값 : \m sepal length (cm) 2.492019
sepal width (cm) 3.090775
petal length (cm) 1.785832
petal width (cm) 1.712096
dtype: float64 '''스케일링 객체를 이용해 학습 데이터 세트로 fit과 transform을 적용하면 테스트 데이터 세트로는 다시 fit을 수행하지 않고 학습 데이터 세트로 fir을 수행한 결과를 이용해 transform 변환을 적용해야 한다.
(=학습 데이터로 fit이 적용된 스케일링 기준 정보를 그래도 테스트 데이터에 적용해야 한다)
from sklearn.preprocessing import MinMaxScaler
import numpy as np
train_array=np.arange(0,11).reshape(-1,1)
test_array=np.arange(0,6).reshape(-1,1)
scaler=MinMaxScaler()
scaler.fit(train_array)
train_scaled=scaler.transform(train_array)
print('원본 train_array 데이터 : ',np.round(train_array.reshape(-1),2))
print('scaled train_array 데이터 : ',np.round(train_scaled.reshape(-1),2))
#scaler.fit(test_array) 테스트 데이터에 다시 fit을 하면 안됨
test_scaled=scaler.transform(test_array)
print('원본 test_array 데이터 : ',np.round(test_array.reshape(-1),2))
print('scaled test_array 데이터 : ',np.round(test_scaled.reshape(-1),2))''' 결과
원본 train_array 데이터 : [ 0 1 2 3 4 5 6 7 8 9 10]
scaled train_array 데이터 : [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]
원본 test_array 데이터 : [0 1 2 3 4 5]
scaled test_array 데이터 : [0. 0.1 0.2 0.3 0.4 0.5] '''
'기타(🎸X) > 빅데이터' 카테고리의 다른 글
| [빅데이터] 파이썬 빅데이터 분석 패키지 - pandas (0) | 2023.05.29 |
|---|---|
| [빅데이터] 파이썬 빅데이터 분석 패키지 - numpy (0) | 2023.05.28 |
| [빅데이터] 데이터 비식별화 기법 (0) | 2023.05.09 |
| [빅데이터] 빅데이터 플랫폼 (0) | 2023.02.25 |
| [빅데이터] 빅데이터 조직 및 인력 (0) | 2023.02.24 |




댓글