1. 배열과 리스트
- 배열 : 메모리의 연속 공간에 값이 채워져 있는 형태의 자료구조
1) 인덱스를 사용하여 값에 바로 접근할 수 있다.
2) 새로운 값을 삽입하거나, 특정 인덱스에 있는 값 삭제가 어렵다.
(값을 삽입, 삭제하려면 해당 인덱스 주변에 있는 값의 이동이 필요함)
3) 배열의 크기는 선언할 때 지정할 수 있으며, 한번 선언하면 크기를 늘리거나 줄일 수 없다.
- 리스트 : 값과 포인터를 묶은 노드라는 것을 포인터로 연결한 자료구조
1) 인덱스가 없음, Head 포인터부터 순서대로 접근해야 한다. (접근 속도가 느림)
2) 포인터로 연결되어 있어 데이터를 삽입하거나 삭제하는 연산 속도가 빠르다.
3) 크기를 별도로 지정하지 않아도 된다.
(리스트의 크기는 정해져 있지 않으며, 크기가 변하기 쉬운 데이터를 다룰 때 적절함)
ex 01) 백준 11720 숫자의 합
ex 02) 백준1546 평균
2. 구간 합
- 구간 합 : 합 배열을 이용하여 시간 복잡도를 더 줄이기 위해 사용하는 특수목적 알고리즘
합 배열을 미리 구해놓으면 기존 배열의 일정 범위의 합을 구하는 시간 복잡도가 O(N)에서 O(1)로 감소한다.
합 배열 정의 : S[i-1] + A[i]
합 배열 공식 : S[i] = S[i-1] +[i]
구간 합 공식 : S[j] - S[i-1]
ex 03) 백준 11659 구간 합 구하기 4
ex 04) 백준 11660 구간 합 구하기 5
ex 05) 백준 10986 나머지 합
3. 투 포인터
- 투 포인터 : 2개의 포인터로 알고리즘의 시간 복잡도를 최적화
<한쪽에서 시작>
ex 06) 백준 2018 수들의 합 5
2018번: 수들의 합 5
어떠한 자연수 N은, 몇 개의 연속된 자연수의 합으로 나타낼 수 있다. 당신은 어떤 자연수 N(1 ≤ N ≤ 10,000,000)에 대해서, 이 N을 몇 개의 연속된 자연수의 합으로 나타내는 가지수를 알고 싶어한
www.acmicpc.net

start_index 오른쪽으로 한 칸 이동 : 연속된 자연수에서 왼쪽 값을 삭제하는 것
end_index 오른쪽으로 한 칸 이동 : 연속된 자연수의 범위를 한 칸 더 확장하는 것
- 투 포인터 이동 원칙
sum > N : sum = sum - start_index; start_index++; //연속 합이 N보다 큰 경우 왼쪽 값 삭제
sum < N : end_index++; sum = sum + end_index; //연속 합이 N보다 작은 경우 자연수 범위 확장
sum == N : end_index++; sum = sum + end_index; count++; //자연수 범위 확장 후 카운트 증가
<양쪽에서 시작>
ex 07) 백준 1940 주몽
1940번: 주몽
첫째 줄에는 재료의 개수 N(1 ≤ N ≤ 15,000)이 주어진다. 그리고 두 번째 줄에는 갑옷을 만드는데 필요한 수 M(1 ≤ M ≤ 10,000,000) 주어진다. 그리고 마지막으로 셋째 줄에는 N개의 재료들이 가진 고
www.acmicpc.net

- 투 포인터 이동 원칙
A[i] + A[j] > M : j--; //번호의 합이 M보다 크므로 큰 번호 index를 내림
A[i] + A[j] < M : j++; //번호의 합이 M보다 작으므로 작은 번호 index를 올림
A[i] + A[j] == M : i++; j--; count++; //양쪽 포인터를 모두 이동시키고 count 증가
ex 08) 백준 1253 좋다
4. 슬라이딩 윈도우
- 슬라이딩 윈도우 : 2개의 포인터로 범위를 지정한 다음 범위를 유지한 채로 이동하며 문제 해결
<정렬 사용>
ex 09) 백준 12891 DNA 비밀번호
12891번: DNA 비밀번호
평소에 문자열을 가지고 노는 것을 좋아하는 민호는 DNA 문자열을 알게 되었다. DNA 문자열은 모든 문자열에 등장하는 문자가 {‘A’, ‘C’, ‘G’, ‘T’} 인 문자열을 말한다. 예를 들어 “ACKA”
www.acmicpc.net

길이가 P일 윈도우를 지정하여 배열 S의 시작점에 놓고
윈도우를 오른쪽으로 밀면서 윈도우에 잡힌 값들이 조건에 맞는지 탐색한다.
<덱으로 구현>
ex 10) 백준 11003 최솟값 찾기
11003번: 최솟값 찾기
N개의 수 A1, A2, ..., AN과 L이 주어진다. Di = Ai-L+1 ~ Ai 중의 최솟값이라고 할 때, D에 저장된 수를 출력하는 프로그램을 작성하시오. 이때, i ≤ 0 인 Ai는 무시하고 D를 구해야 한다.
www.acmicpc.net

- 덱 : 양 끝에서 데이터를 삽입하거나 삭제할 수 있는 자료구조
왼쪽의 addFirst(), removeFirst() 함수가 삽입 삭제 역할을 하고
오른쪽의 addLast(), removeLast() 함수가 삽입, 삭제 역할을 한다.

(2, 5)는 (3, 2)보다 값이 크므로 (2, 5)를 덱에서 제거(removeLast)한다.
(1, 1)는 (3, 2)보다 값이 작으므로 탐색을 멈추고 (3,2)를 덱에 저장(addLast)한다.
정리를 마친 덱의 인덱스 범위 1~3에서 최솟값을 찾는다, (1,1)

계속해서 새 노드를 추가하고 인덱스 범위가 슬라이딩 윈도우를 벗어났을때 제거한다.
제거가 끝난 후 최솟값을 찾는다. (3, 2)
5. 스택과 큐
- 스택 : 삽입과 삭제 연산이 후입선출(LIFO)로 이뤄지는 자료구조
삽입과 삭제가 한 쪽에서만 일어난다.
깊이 우선 탐색(DFS) , 백트래킹 종류의 코딩 테스트에 효과적이다.
재귀 함수 알고리즘 원리와 일맥상통하다.
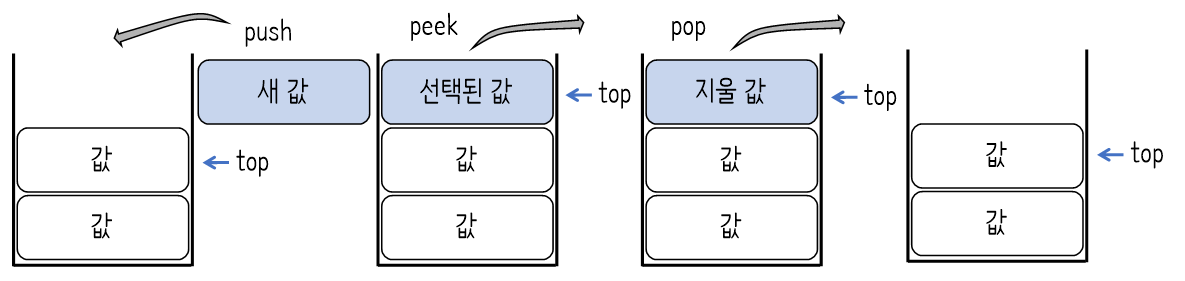
용어
top : 삽입과 삭제가 일어나는 위치
연산
push : top 위치에 새로운 데이터를 삽입하는 연산
pop : top 위치에 현재 있는 데이터를 삭제하고 확인하는 연산
peek : top 위치에 현재 있는 데이터를 단순 확인하는 연산
-큐 : 삽입과 삭제 연산이 선입선출(FIFO)로 이뤄지는 자료구조
먼저 들어온 데이터가 먼저 나가고 삽입과 삭제가 양방향에서 이뤄진다.

용어
rear : 큐에서 가장 끝 데이터를 가리키는 영역
front : 큐에서 가장 앞의 데이터를 가리키는 영역
연산
add : rear 부분에 새로운 데이터를 삽입하는 연산
poll : front 부분에 있는 데이터를 삭제하고 확인하는 연산
peek : 큐의 맨 앞(front)에 있는 데이터를 확인할 때 사용하는 연산
ex 11) 백준 1874 스택 수열
ex 12) 백준 17298 오큰수
ex 13) 백준 2164 카드2
ex 14) 백준 11286 절댓값 힙
'기타(🎸X) > 알고리즘' 카테고리의 다른 글
| [Java/알고리즘] 디버깅의 중요성 (0) | 2022.09.30 |
|---|---|
| [Java/알고리즘] 알고리즘과 시간 복잡도 / 로직 개선하기 (3) | 2022.09.29 |


댓글